

LISREL 12破解版是功能强大的用于结构方程式建模工具,此外还提供一些重要的数据处理和基本统计分析、分层和非线性建模、广义线性建模和广义线性建模等工具和功能,它包括64位统计应用程序LISREL,PRELIS,MULTILEV,SURVEYGLIM和MAPGLIM,功能非常的全面和强大,最先进的技术,最稳定的使用,是非常给力的统计软件!适用于Windows的LISREL 10以SPS,SAS,STATA,Microsoft Excel,Statistica,SYSTAT,BMDP等格式导入外部数据作为LISREL系统文件(LSF)。支持使用和生成的各种文件。能够将测量模型拟合到SPSS数据集,以及使用潜在变量拟合结构方程模型等等,更多的功能大家可以来本站下载体验,安装包中提供破解补丁,有需要的朋友不要错过了!
新功能介绍
1、背景
最初引入结构方程建模(SEM)作为一种分析协方差或相关矩阵的方法。通常,将这个矩阵读入LISREL并通过最大似然估计模型。如果可获得原始数据而没有缺失值,则也可以先使用PRELIS估计渐近协方差矩阵,以获得标准误差和卡方的可靠估计。
现代结构方程建模基于原始数据。使用LISREL10,如果LISREL数据系统文件或文本文件中有原始数据,则可以将数据读入LISREL并使用SIMPLIS语法或LISREL语法来建立模型。
LISREL10包含对LISREL9用户报告的所有错误的修复。接下来将总结新的LISREL功能。
2、使用单个数据文件进行多组分析
实际上,许多多元数据集是来自多个组的观察值。这些群体的例子包括性别,语言,政党,国家,学院,学院,学校等。
LISREL可用于将多个组结构方程模型拟合到多个组数据。提供了传统的统计方法,例如最大似然(ML),鲁棒最大似然(RML),加权最小二乘(WLS),对角加权最小二乘(DWLS),广义最小二乘(GLS)和未加权最小二乘(ULS)用于完整的多个组数据,而完全信息最大似然(FIML)方法可用于不完整的多个组数据。
在以前的LISREL版本中,要求用户为每个组创建单独的数据文件。假设要分析的组由在八个国家/地区收集的数据组成,则含义是必须创建八个数据集才能适合多组结构方程模型。
LISREL10中实现的一项新功能使研究人员可以使用包含一个组变量的单个数据集,该组变量可以通过以下方式定义:
在打开LISREL系统文件(.lsf)时使用数据菜单
通过在语法文件中的任何位置插入$GROUPS=<组变量名称>行。
3、分组关系和离散关系生存数据的模型
当根据某个事件的发生以固定间隔重复测量对象时,或者仅在分组时间间隔内才知道事件的确切时间时,分组时间生存数据的模型可用于分析故障时间数据。。另外,通常情况是,观察到的对象被嵌套在集群中(即,学校,公司,诊所),或根据重复事件进行重复测量。在这种情况下,使用假定观测独立的分组时间模型是有问题的,因为来自同一聚类或主题的观测通常是相关的。
对于聚类和/或重复的数据,包括随机效应的模型提供了一种方便的方法来考虑相关生存数据中的关联。
几位作者已经注意到序数回归模型(使用互补对数-对数和逻辑链接函数)与成组时间和离散时间的生存分析模型之间的关系。在LISREL10中,实现了序数随机效应回归模型的一般化,以处理相关的分组时间生存数据。该模型适应多元正态分布的随机效应,此外,还允许模型协变量具有通用形式。
假设存在比例或部分比例的风险或赔率模型,则使用多维正交算法对随机效应的分布进行数值积分,以实现最大边际似然解。参考指南“用于分组数据的生存模型.pdf”包含示例和参考,可通过联机“帮助”菜单进行访问。
4、序数结果模型,比例赔率与非比例赔率假设
术语“普通”适用于以一系列有序类别测量感兴趣的响应度量的变量。此类变量的示例包括李克特量表和严重程度的精神病学评分。名义和顺序结果模型可以看作是二元结果模型的概括。当结果变量不是二分法或不是真正连续时,顺序模型就变得很重要。如果在连续模型中分析了序数结果,则此类模型可以得出序数变量范围之外的预测值。与二进制数据一样,必须进行某种转换或链接功能以防止这种情况发生。当将连续模型应用于序数结果时,它也可以产生相关的残差和回归变量,因为连续模型未考虑序数结果的上限和下限影响。然后,这可能导致回归系数的估计有偏差,并且在所讨论的序数变量高度偏斜时,这是最关键的。
许多研究人员已经在开发用于顺序响应数据分析的方法方面进行了广泛的工作。这些发展集中在将二分变量的方法扩展到顺序响应数据上,并且主要是在逻辑和概率回归模型方面。比例赔率模型是顺序数据分析的常见选择。在LISREL10中,可以使用比例和非比例赔率模型进行拟合,以使用卡方差检验检验比例赔率假设。参考指南“比例和非比例odds.pdf的模型”包含示例和参考,可通过联机“帮助”菜单进行访问。
5、非正态下C1统计的P值
现代结构方程建模基于原始数据。使用LISREL10,如果LISREL数据系统文件或文本文件中有原始数据,则可以将数据读入LISREL并使用SIMPLIS语法或LISREL语法来建立模型。不再需要使用PRELIS估计渐近协方差矩阵并将其读入LISREL。渐近协方差矩阵和模型的估计现在在LISREL中完成。还可以在LISREL中使用EM或MCMC多种插补方法,以使模型适合插补数据。
6、结合LISREL和PRELIS功能
Satorra&Bentler(1978)指出,卡方C1的渐近分布是自由度为1的卡方线性组合的分布,其中线性组合的系数为d(d=自由度)UW_NNT的非零特征值,其中U是在Satorra&Bentler(1978)中定义的,也是在文档“LISREL9的新功能”(在“LISREL用户和参考指南”中提供)的等式(45)中定义的,而W_NNT是非正态下观测变量的方差和协方差的渐近协方差矩阵的估计,通常称为ACM矩阵。
LISREL10估计线性组合的d个特征值和p值。本质上,这使得其他卡方C2,C3,C4和C5不再那么重要,因为它们仅基于分布的近似值,而仅使用特征值的均值和方差。
7、使用统计/传输进行数据转换
数据导入/导出软件已从统计/传输版本13升级到最新发布的版本14。
可用的新功能选择统计/传输版本14
版本14增加了对以下格式的支持:
Stata15/MP
BayesiaLab(仅写)
JSON-Stat(只读)版本14对于以下内容具有更大的限制:
Excel文件>4GB
SAS文件>32K变量
Stata文件>32K变量
dBASE>2GB
8、FIML用于序数和连续变量
LISREL10支持针对简单随机样本和复杂调查数据的序数和连续变量混合的结构方程建模。
LISREL实现允许使用设计权重来将SEM模型拟合为连续和有序清单变量的混合物,无论是否具有缺失值以及可选的层和/或簇变量规范。它还处理健壮的标准误差估计和拟合统计量的卡方拟合度调整的问题。
此方法基于自适应正交,并且用户可以指定以下四个链接功能中的任何一个:
洛吉特
概率
互补日志
日志日志
\orfimlex和\ls9ex文件夹中提供了说明此功能的示例。
9、三级多级广义线性模型
聚类或多阶段样本设计经常用于具有固有层次结构的总体。忽略数据的层次结构具有严重的意义。使用替代方法(如将信息汇总和分解到另一个级别)可能会导致预测变量之间的共线性增加,以及估计的较大或有偏差的标准误差。
称为广义线性模型(GLIM)的模型的收集已成为重要且实用的统计工具。GLIM的基本思想是将标准回归适应各种不同的数据。变量可以是二分法,序数(如5点李克特量表),计数(逮捕记录数)或名义变量。这样做的动机是定制将结果与相关自变量连接的回归关系,使其适合因变量的属性。LISREL8.8实施了将广义线性模型(GLIM)拟合到调查数据的统计理论和方法。
来自社会经济科学领域的研究人员经常将这些方法应用于多层次数据,因此,得出了不合适的结果。用于多级数据分析的LISREL统计模块允许设计权重。有两种估计方法,MAP(后验分布的最大化)和QUAD(自适应正交),用于将广义线性模型拟合到多级数据。LISREL多级广义线性模型模块(MGLIM)允许进行多种采样分配和链接功能。
LISREL10MGLIM模块还包括零膨胀的Poisson模型和零膨胀的Negative-Binomial模型,并打印结果以用于固定效应的单位特定和总体平均估计。
\mglimex文件夹中的示例说明了这些功能。
10、连续结果变量的四级和五级多层线性模型
社会科学研究通常需要对数据进行分层结构分析。经常引用的多级数据示例是一个数据集,其中包含对嵌套在学校内的孩子和嵌套在教育部门内的孩子的测量。
人们已经充分认识到需要考虑采样方案的统计模型,并且已经表明,在简单随机采样方案的假设下对调查数据进行分析可能会产生误导性的结果。
多层模型在复杂调查数据的建模中特别有用。聚类或多阶段样本设计经常用于具有固有层次结构的总体。忽略数据的层次结构具有严重的意义。使用替代方法(如将信息汇总和分解到另一个级别)可能会导致预测变量之间的共线性增加,以及估计的较大或有偏差的标准误差。为了解决有关对调查数据进行适当分析的担忧,LISREL连续数据多级模块现在还可以处理多达五个级别,并提供了一个选项,供用户在第1、2、3、4或5级上包括设计权重。层次结构。
在\mlevelex文件夹中给出了示例。
文件扩展名
所有LISREL语法文件扩展名.LIS(因为LISREL9,以前,LS8),所有PRELIS语法文件扩展名.prl(因为LISREL9,以前.pr2)。LISREL电子表格已重命名为LISREL数据系统文件,并具有扩展名.lsf(因为LISREL9,以前是.psf)。
为了确保向后兼容,用户仍然可以使用.psf文件运行以前创建的语法文件,但是要使用图形用户界面打开现有的.psf文件,用户必须将其重命名为.lsf。
安装破解教程
1、在本站下载并解压,如图所示,得到以下内容
2、双击LISREL10.exe运行安装,勾选我接受许可证协议条款
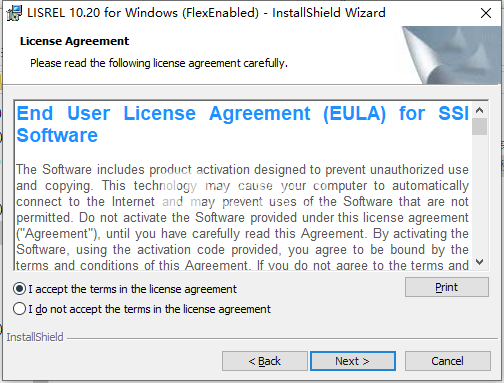
3、选择软件安装路径
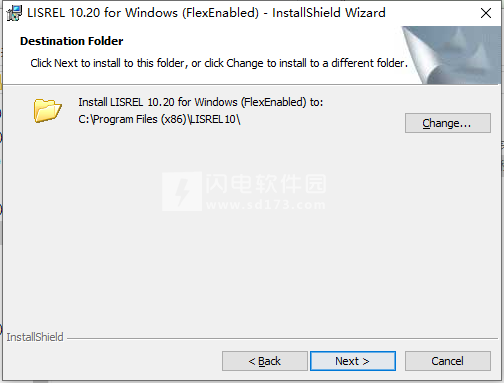
4、勾选我已经阅读了有关LISREL示例文件的通知。
5、安装完成,退出向导
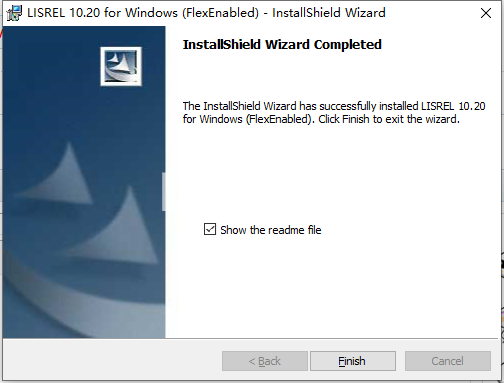
6、将破解文件夹中的文件复制到安装目录中,默认路径C:\Program Files (x86)\LISREL10
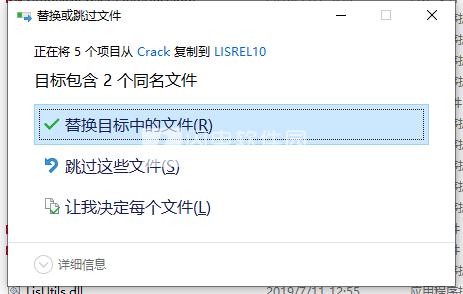
7、创建系统变量
变量名称:SSISOFT_LICENSE_FILE
变量值:C:\Program Files (x86)\LISREL10\license.dat(默认路径)
闪电小编说明:
LISREL是用于标准和多层结构方程建模的64位应用程序。这些方法可用于关于分类变量和连续变量的完整和不完整的复杂调查数据,以及关于分类变量和连续变量的完整和不完整的简单随机样本数据。LISREL可用于将多个组结构方程模型拟合到多个组数据。LISREL不完整数据的FIML估计方法用于将测量模型拟合到两个多元数据集,许多流行的统计方法都基于数学模型,这些数学模型假定数据遵循正态分布。其中最明显的是计划实验的方差分析和自变量和因变量的一般分析的多元回归。在许多情况下,正常性假设是不合理的。因此,使用假定正常的方法可能无法令人满意地执行。在这些情况下,不需要数据具有正态分布的其他替代方法很有吸引力。LISREL帮助研究人员提供一种相当有影响力和灵活性的方法来检查各种群体差异。 它提供称为修改索引的指示性信息,帮助研究人员识别等式约束。LISREL可以帮助用户识别需要包含在模型中的交互效果以及不需要包含在模型中的交互效果。 指示信息可用于诊断模型规范。软件无法下载?不知道解压密码?微信关注订阅号"闪电下载"获取
本帖长期更新最新版 请收藏下载!版权声明:本站提的序列号、注册码、注册机、破解补丁等均来自互联网,仅供学习交流之用,请在下载后24小时内删除。


















